Hadoop 海量數(shù)據(jù)存儲(chǔ)與計(jì)算的革命性解決方案
在當(dāng)今大數(shù)據(jù)時(shí)代,企業(yè)和組織面臨著前所未有的數(shù)據(jù)挑戰(zhàn)。傳統(tǒng)的數(shù)據(jù)處理系統(tǒng)已經(jīng)難以應(yīng)對(duì)PB級(jí)別的海量數(shù)據(jù),而Hadoop作為開源分布式系統(tǒng)的杰出代表,為海量數(shù)據(jù)的存儲(chǔ)和計(jì)算提供了革命性的解決方案。
Hadoop的核心架構(gòu)與組件
Hadoop生態(tài)系統(tǒng)主要由兩大核心組件構(gòu)成:HDFS(Hadoop分布式文件系統(tǒng))和MapReduce計(jì)算框架。
HDFS:可靠的數(shù)據(jù)存儲(chǔ)基石
HDFS采用主從架構(gòu)設(shè)計(jì),由NameNode和DataNode組成。NameNode負(fù)責(zé)管理文件系統(tǒng)的元數(shù)據(jù),而DataNode則存儲(chǔ)實(shí)際的數(shù)據(jù)塊。這種設(shè)計(jì)具有以下顯著優(yōu)勢(shì):
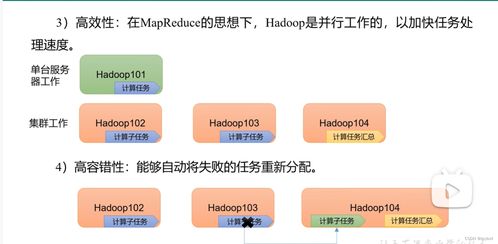
- 高容錯(cuò)性:數(shù)據(jù)自動(dòng)復(fù)制到多個(gè)節(jié)點(diǎn),單點(diǎn)故障不會(huì)導(dǎo)致數(shù)據(jù)丟失
- 高吞吐量:支持大規(guī)模數(shù)據(jù)集的并行讀寫操作
- 可擴(kuò)展性:能夠輕松擴(kuò)展到數(shù)千個(gè)節(jié)點(diǎn),存儲(chǔ)EB級(jí)別的數(shù)據(jù)
- 成本效益:可在廉價(jià)的商用硬件上運(yùn)行
MapReduce:高效的數(shù)據(jù)處理引擎
MapReduce采用"分而治之"的策略,將復(fù)雜的數(shù)據(jù)處理任務(wù)分解為兩個(gè)階段:
Map階段:將輸入數(shù)據(jù)分割成獨(dú)立的塊,由不同的節(jié)點(diǎn)并行處理
Reduce階段:將Map階段的輸出進(jìn)行匯總,生成最終結(jié)果
這種計(jì)算模型特別適合批處理任務(wù),能夠高效處理TB甚至PB級(jí)別的數(shù)據(jù)。
Hadoop的生態(tài)系統(tǒng)擴(kuò)展
除了核心組件,Hadoop還擁有豐富的生態(tài)系統(tǒng):
- HBase:分布式列式數(shù)據(jù)庫(kù),支持實(shí)時(shí)數(shù)據(jù)訪問(wèn)
- Hive:數(shù)據(jù)倉(cāng)庫(kù)工具,提供類SQL查詢功能
- Pig:高級(jí)數(shù)據(jù)流語(yǔ)言,簡(jiǎn)化MapReduce編程
- Spark:內(nèi)存計(jì)算框架,大幅提升處理速度
- ZooKeeper:分布式協(xié)調(diào)服務(wù)
Hadoop在行業(yè)中的應(yīng)用
互聯(lián)網(wǎng)行業(yè)
各大互聯(lián)網(wǎng)公司使用Hadoop進(jìn)行用戶行為分析、推薦系統(tǒng)構(gòu)建、日志處理等。例如,F(xiàn)acebook使用Hadoop集群存儲(chǔ)超過(guò)100PB的數(shù)據(jù),每天處理數(shù)PB的用戶數(shù)據(jù)。
金融行業(yè)
銀行和金融機(jī)構(gòu)利用Hadoop進(jìn)行風(fēng)險(xiǎn)控制、欺詐檢測(cè)、客戶畫像分析,能夠?qū)崟r(shí)處理海量的交易數(shù)據(jù)。
電信行業(yè)
電信運(yùn)營(yíng)商使用Hadoop分析用戶通話記錄、網(wǎng)絡(luò)流量數(shù)據(jù),優(yōu)化網(wǎng)絡(luò)資源配置,提升服務(wù)質(zhì)量。
Hadoop的技術(shù)優(yōu)勢(shì)
- 線性擴(kuò)展能力:通過(guò)增加節(jié)點(diǎn)即可線性提升存儲(chǔ)和計(jì)算能力
- 容錯(cuò)機(jī)制:自動(dòng)處理節(jié)點(diǎn)故障,確保系統(tǒng)持續(xù)運(yùn)行
- 數(shù)據(jù)本地化:計(jì)算任務(wù)盡可能在數(shù)據(jù)存儲(chǔ)節(jié)點(diǎn)執(zhí)行,減少網(wǎng)絡(luò)傳輸
- 開源生態(tài):活躍的社區(qū)支持和豐富的第三方工具
挑戰(zhàn)與發(fā)展趨勢(shì)
盡管Hadoop在大數(shù)據(jù)處理方面表現(xiàn)出色,但也面臨一些挑戰(zhàn):
- 實(shí)時(shí)處理能力相對(duì)較弱
- 運(yùn)維復(fù)雜度較高
- 對(duì)技能要求較高
Hadoop正朝著實(shí)時(shí)化、云原生、智能化方向發(fā)展,與容器技術(shù)、機(jī)器學(xué)習(xí)等新興技術(shù)深度融合。
結(jié)語(yǔ)
Hadoop作為大數(shù)據(jù)技術(shù)的基石,已經(jīng)證明了自己在處理海量數(shù)據(jù)方面的卓越能力。隨著技術(shù)的不斷演進(jìn),Hadoop必將在數(shù)字經(jīng)濟(jì)時(shí)代繼續(xù)發(fā)揮關(guān)鍵作用,為各行各業(yè)的數(shù)據(jù)驅(qū)動(dòng)決策提供強(qiáng)有力的支撐。對(duì)于任何需要處理大規(guī)模數(shù)據(jù)的企業(yè)來(lái)說(shuō),掌握和運(yùn)用Hadoop技術(shù)已經(jīng)成為必備的核心競(jìng)爭(zhēng)力。
如若轉(zhuǎn)載,請(qǐng)注明出處:http://www.eb315.com.cn/product/27.html
更新時(shí)間:2026-06-15 19:24:33